And to top it off a cool video on all the sorting algorithms:
Friday 6 December 2013
Sorting Algorithm Efficiency Review - Week 10
As part of a review for the final exam I'll write about the efficiency's of different sorting algorithms in reference to their Big-Os. First we have selection sort, it is nice to know as it is simple, it finds the largest or smallest element and puts it into a sorted list and take it out of the unsorted list until the unsorted list is empty. It has efficiency O(n^2) as it is usually a nested for-loop. Second, merge sort, I always liked merge sort because the idea seemed clever. It splits the list in two repeatedly and then merges them together, called a "divide and conquer algorithm. It has efficiency O(n logn) as it is a recursive call on a split of base 2. Lastly, there is quick sort (my least favorite). Good for lists usually as it has O(n logn) for best case scenarios, but in worst case it has efficiency O(n^2), it picks an element then compares it to all others and inserts it. Comparing these three, the best would be merge sort as it consistently is O(n logn), then quick sort as it sometime is great, and then lastly selection sort as it always goes through the whole list with O(n^2).
And to top it off a cool video on all the sorting algorithms:
And to top it off a cool video on all the sorting algorithms:
Tuesday 26 November 2013
Finals and Unfortunate Events - Week 9
An unfortunate event has occurred, my laptop has broken. However I have found a temporary replacement. The main issue, however, is that my files have all been lost :( . Always save important notes on a flash drive. My exercises, labs, and assignments to review are now gone. As well as my notes for other classes. Otherwise, I guess re-doing every assignment, exercise, and lab would be great review?
Topics to review immediately however would be memoize, maps, and properties. I find properties to be something really nice and reminds me of rewriting operators like in c++. It really seems useful for making classes work together, comparable, addable, etc. Maybe even makes lists that you can add elements to with a simple + sign. Memoize is quite a clever way to reduce computations within a function, it helps me see now what exactly the purpose of a cache is. Although I wonder how this would be done outside of python without dictionaries, are there similar built in data structures or would we make our own? I can't think of any in Java off the top of my head. Reduce mapping seems like a really simple and quick shortcut to computing the sum/multiplication/reduction of a list of things, rather than using built in functions or making your own. It also is another way to potentially save memory, like caches!
Topics to review immediately however would be memoize, maps, and properties. I find properties to be something really nice and reminds me of rewriting operators like in c++. It really seems useful for making classes work together, comparable, addable, etc. Maybe even makes lists that you can add elements to with a simple + sign. Memoize is quite a clever way to reduce computations within a function, it helps me see now what exactly the purpose of a cache is. Although I wonder how this would be done outside of python without dictionaries, are there similar built in data structures or would we make our own? I can't think of any in Java off the top of my head. Reduce mapping seems like a really simple and quick shortcut to computing the sum/multiplication/reduction of a list of things, rather than using built in functions or making your own. It also is another way to potentially save memory, like caches!
Saturday 23 November 2013
Properties and Reductions - Week 8
This week we discussed the built in properties and map reduce. Properties allows us to change how variables are assigned, retrieved, and deleted from a class. Essentially it allows us to dummy-proof a class so that someone can't break it by only accepting certain inputs like with regex tree nodes. In class we haven't had to do something like this because we expect certain types of inputs, but outside in the real world we should account for things like this when working with other people.
Map reduce just seems like a nice built in function to use for quick computing of lists. The lab brought us back to sorting efficiency's, showing how much a few lines of code can effect the number of operations in the long run. It also showed how with the number of elements in something being sorted, a type of sort may be better at the start but much worse at the end.
Map reduce just seems like a nice built in function to use for quick computing of lists. The lab brought us back to sorting efficiency's, showing how much a few lines of code can effect the number of operations in the long run. It also showed how with the number of elements in something being sorted, a type of sort may be better at the start but much worse at the end.
Tuesday 12 November 2013
Where did all the days go? - Week 7
Haven't made a post in quite a while, so I'll reminisce about the past assignment: regex trees. Parsing regex trees was quite straight forward however matching proved to be a challenge of trials and errors due to edge cases. It came down to correct ranges in the end for the troublesome star nodes. Edge cases like (e*|1)* were troublesome, creating infinite loops. Results show all the auto-marker test cases worked however I assume TAs will try to break the code and go over the documentation.
In preparation for the test I have done what Danny said to do in class, gone over the past labs, examples in class, assignment, and past exercises. I still feel somewhat unprepared, it is probably from the pressure of the new CS subject post requirements.
In preparation for the test I have done what Danny said to do in class, gone over the past labs, examples in class, assignment, and past exercises. I still feel somewhat unprepared, it is probably from the pressure of the new CS subject post requirements.
Tuesday 29 October 2013
Run Times Means Fun Times! - Week 5
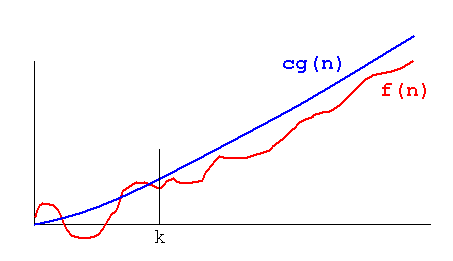
CSC165 and CSC148 are overlapping! Everything in CS relates to Big-Oh, but I honestly find it a bit confusing. I suppose thinking of it in a more broad scope would help, rather than the bounds being of the functions themselves they are of the growth of the functions. No matter what you do to n with constants, it still will grow at a similar rate as another n if it is multiplied by constants. It's nice to see the sorts we've learned having a more measurable concept of efficiency, n, logn, etc.
Friday 25 October 2013
Trees, Binary, Tuples. - Week 4
Binary trees are very interesting with all their applications, like the ability to use nodes in a queue and such. The exercise was quite straight forward, with the exception of part b in which I kept getting lists within my node lists but a simple list comprehension solved my problem. I managed to solve the exercise without helper functions thanks to tuples, something that I was introduced to this year as I had programmed in java. The usefulness of tuples has actually become very apparent now, it really simplifies things when I can return a small tuple.
Wednesday 16 October 2013
Testing Shenanigans and Binary Trees - Week 3
Today I had my first mid-term, which was CSC148, it taught me that I need to really get back into my test-taking habits. First of all: read the question carefully. The number one rule that I apparently forgot, when glazing over i ** 2 my brain thought, "Oh! i multiplies 2" rather than "i to the power of 2". And of course not diving into a question but rather thinking about how to solve it, because the latter in the long run wastes less time.
For indentations I've developed the habit of pressing four spaces. Thank you python! With trees and their preorder, postorder, and inorder everything seems to revolve around recursion. While I learned how to make these trees from simple input, I never really learned how to make trees from the preorder and postorder. Quite an interesting task, it required much more thinking and pen and paper than typing. Ever since my first difficult computer science assignment (the tour of Anne Hoy) I've been thinking things out first on paper as it really does help. It has shown me that in the end, everything boils down to recursion when it comes to trees. Recursion is great, when you understand it.
Subscribe to:
Posts (Atom)